Direct File Input in a Workflow
You can directly upload a CSV file to a workflow. After the file is uploaded, you can select the file as a data object or reference specific data fields of the file using Liquid template language in all tasks of the workflow.
To use direct file input, you need to complete the following settings.
- Go to the Settings tab of the workflow.
- In the Workflow Triggers section, turn off Callout.
- In the Mapped Input Fields and Params section, configure the input field settings for the file.
- Select Files in the Object list.
- Specify a name in the Field Name text box to identify the file.
- Tick Required to have the workflow prompt you to upload a file.
- Select File-Field in the Data Type list.
- Click Update to save the settings.
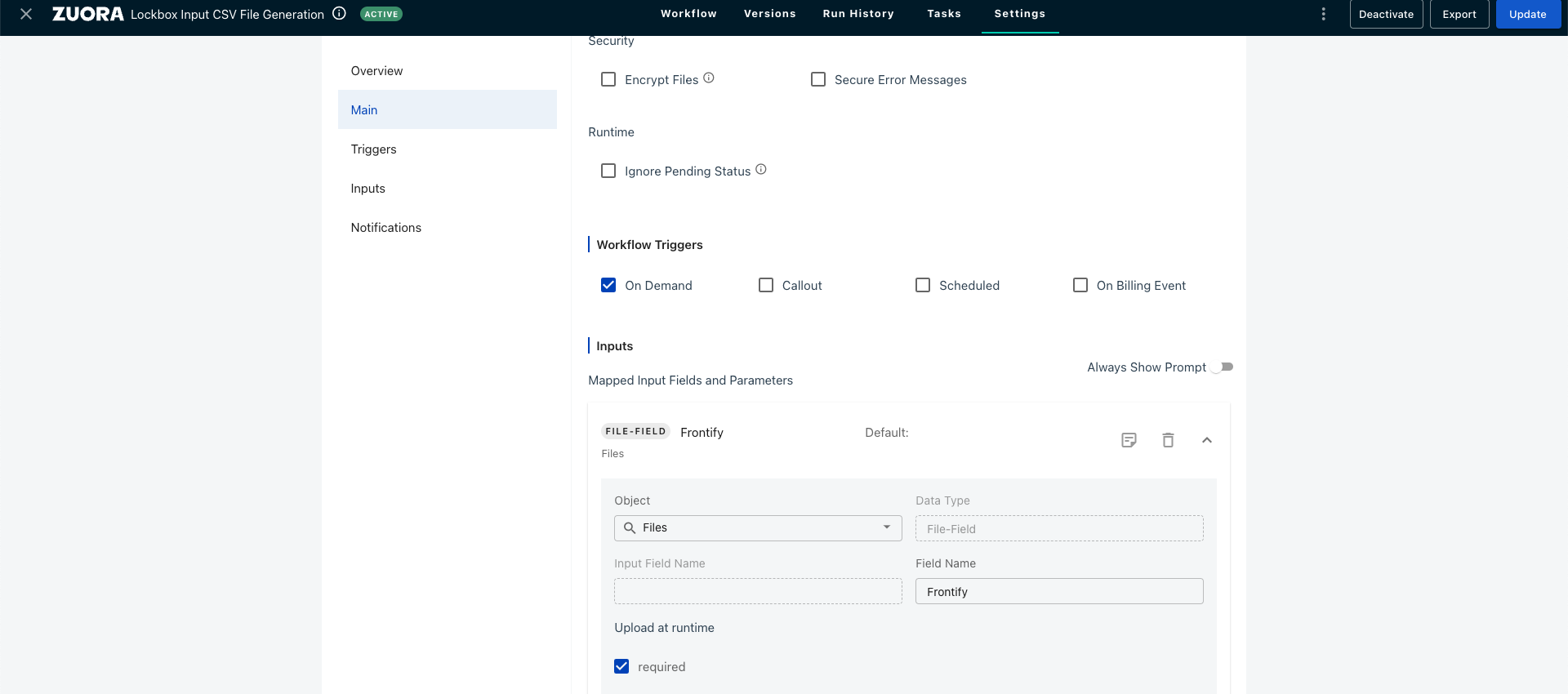
When you manually run the workflow, a window will display prompting you to upload the file.
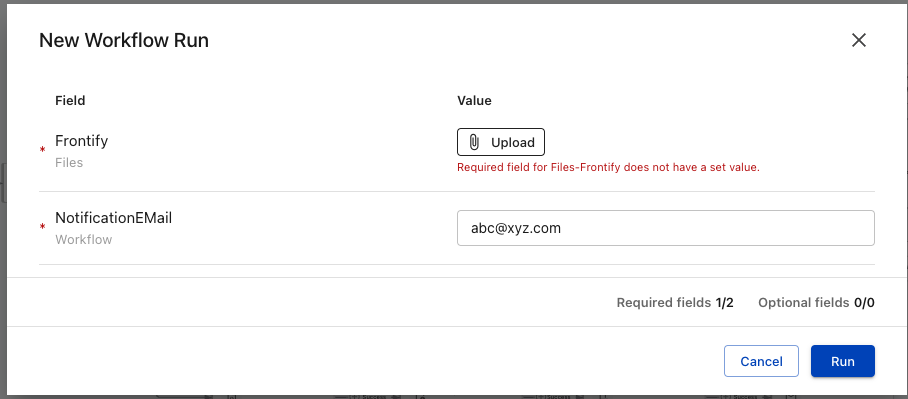
After the file is uploaded, you can select this file from data object lists in tasks or reference this file using Liquid templates in the format of Data.<file_name>.<field_name>.<field_name>.
For example, if we have uploaded a file with the file name file_2 as shown above, we can select this file in an iterate task.
Parse and break up the data in the uploaded File
If you need to process the data entries separately, you can add an iterate task to parse and break up the data in the file.
If you want to iterate unique fields, you must manually enter the unique field, because the data in the file is not parsed until the workflow is run.
Determine the data structure of the payload
If you are not sure about the data structure or the exact data fields to be used in Liquid statements, you can test run the workflow. Ensure you have at least one task subsequent to the iterate task.
When the workflow is completed, start the Swimlane on the task after the iterate task.
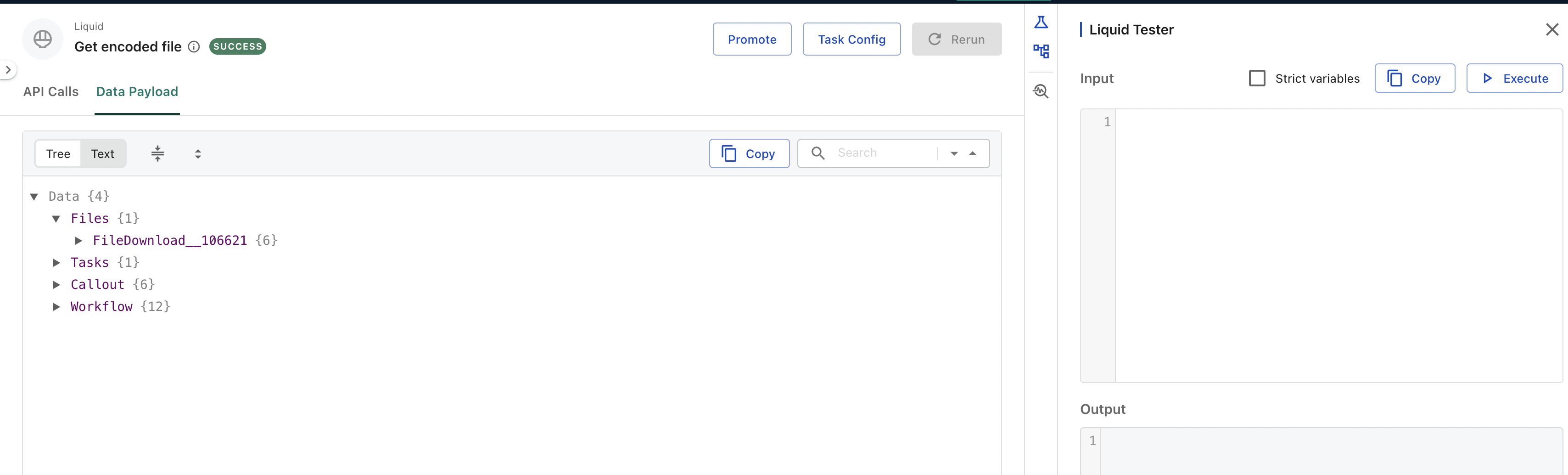
You can find the data structure of the payload from the bottom left. Use the Liquid Tester to test Liquid statements. When you get a desirable statement, copy it and paste to the target task. To edit a task in Swimlane, select the task and click Workflow Task Config to open the task editing window.
Data payload extraction
The iterate task extracts headers from the CSV file and creates a nested data structure based on the headers. It accepts [.] or [:] as the field delimiter and trims spaces within each field. Finally, it connects different levels of fields using [.]. For example, a header Account : Account Id in a CSV file will be parsed as Account.AccountId. To access the value, you can use this Liquid statement:
{{ Data.<file_name>.Account.AccountId }}