Logic: Iterate
This task iterates the input data one entry at a time by default. If you set Iteration Type to Unique-Field, it iterates by unique values of data fields.
The input data can be from:
- a data export or query task
- other tasks that output CSV files
- direct file input by users
You must define a task after an iterate task with the For Each condition to handle further data processing for each item or unique field value.
Optionally, you can define a downstream task for the On Complete or On Failure condition.
Workflow will start the On Complete route when all instances of the iterated task are completed. The On Complete task will wait three hours at maximum for all instances of the iterated task to complete.
Task Settings
- Object: The input data object. It can be a data object in the payload, or a file generated by an export task or uploaded by the user.
- Iteration Type: If the logic of the subsequent tasks is based on unique values of a data field, select Unique-Field. Otherwise, use Default (Every Item).
- Chunking: If the subsequent task processes multiple items at a time, specify a number as the chunking size. Chunking is useful for bulk creating, updating, or deleting operations.
- File Type: The input file type. Only CSV and fixed-width input files are supported.
- CSV: This is the default option. If this option is selected, you can specify a header filter to help Workflow locate the header row.
- Fixed-width: Select this option if the input is a fixed-width text file. If this option is selected, the Iterate task will iterate the lines in the fixed-width file. You can specify the numbers of lines to skip from the beginning and from the end.
Use the Encoding dropdown list to specify the character-encoding scheme of the input file.
If a single record in the fixed-width file spans multiple rows (lines), you can add rows and specify the starting and ending indexes of the characters that you want to extract.

- Number of Rows to Skip from the Beginning (Optional): You can skip a specified number of rows from the top of a CSV file. You can also skip the trailer record of the file.
The maximum number of heading rows that can be skipped is 25.
- Paths of Data Payload Values to Delete: You can delete data that is not needed, to reduce task payload size and improve performance. The payload path is in the format of
Data.<objectName>.
Examples
If the preceding task is an export task, the file containing the exported data will be available in the Object list of the iterate task. The file name is in the format of <object_name>_<a_number>.csv.zip.
If the preceding task is a query task or other tasks that save data in the payload, the Object list can be like the following:

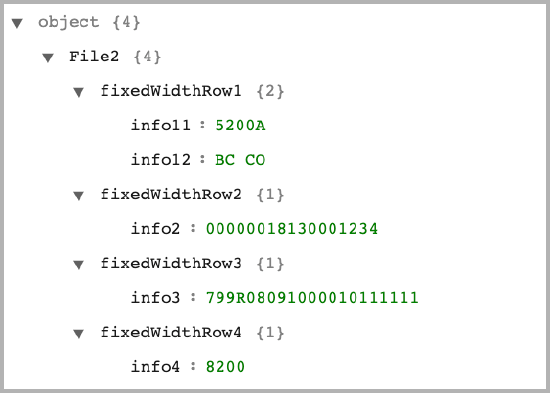
If you are iterating over a fixed-width file, in which each record spans multiple rows, you can add rows and specify the starting and ending indexes of characters that you want to extract. For example, the following fixed-width file contains five records, each spans four rows. There is a starting row and an ending row.
1011234567890 0910000190909140559A094101ABC COMPANY WELLS FARGO BANK 5200ABC COMPANY 2222222222PPDPREMIUM SEP 120909120001091000017000001 6260515012990123456 00000018130001234 BOB B BROWN SR 1091000010111111 799R08091000010111111 05150129 091000010001234 820000000200051501290000000018130000000000002222222222 091000010000001 5200ABC COMPANY (R) 2222222222PPDPREMIUM SEP 120909120001091000019000002 6262642790914321123443 00000050000001333 Ronald Reed 1091000010222222 799R01091000010222222 26427909 091000010002345 820000000200264279090000000050000000000000002222222222 091000010000002 5200ABC COMPANY 1111111111PPDPREMIUM SEP 120909120001091000017000003 6260841006385656565 00000039920001357 Sheryl S Smith 1091000010333333 799R07091000010333333 08410063 091000010003456 820000000200084100630000000039920000000000001111111111 091000010000003 5200ABC COMPANY 1111111111PPDPREMIUM SEP 120909120001091000017000004 6261211330050120120120 00000000000001579 WAYNE WILSON 1091000010444444 798C02091000010444444 12113300121140218 091000010004567 820000000200121133000000000000000000000000001111111111 091000010000004 5200ABC COMPANY 2222222222PPDPREMIUM SEP 120909120001091000017000005 6260653054369898989898 00000000000002345 GEORGE GONZALES 1091000010555555 798C05091000010555555 0653054337 091000010005678 820000000200065305430000000000000000000000002222222221 091000010000005 9000005000003000000100058631944000000010805000000000000
You can skip the first and the last row, then add four rows in the settings.

After the workflow is run, the first record of the iteration looks like this: